
Relacione as frações constituintes de solos com sua respectiva escala granulométrica em termos de dimensões das partículas. 1.Areia 2.Pedregulho 3.Argila 4.Silte ( ) partículas com dimensões inferiores a 0,005 mm ( ) partículas com dimensões entre 0,05 mm e 0,005 mm ( ) partículas com dimensões entre 4,8 mm e 0,05 mm ( ) partículas com dimensões entre 76 mm e 4,8 mm A relação correta, de cima para baixo, é:
Considere a seguinte definição: Piso rígido e geralmente polido, com juntas de dilatação, moldado in loco, à base de cimento com agregado de mármore triturado. O tipo de piso a que se refere a definição supracitada é:
A ABNT define quatro tipos de telhas cerâmicas. Uma telha do tipo composta de encaixe é a:
A Norma Regulamentadora nº 18 (NR-18) regulamenta o
Programa de Condições e Meio Ambiente de Trabalho na
Indústria da Construção (PCMAT). Esse é um programa que
estabelece procedimentos de ordem administrativa, de
planejamento e de organização, que objetivam a implantação de
medidas de controle e sistemas preventivos de segurança nos
processos, nas condições e no meio ambiente de trabalho na
Indústria da Construção.
Em relação ao normatizado na NR-18 para o PCMAT, é correto
afirmar que:
A figura abaixo mostra na parte esquerda um desenho
elaborado no Software Autocad.
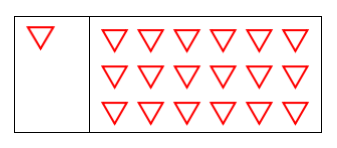
O comando que, executado uma única vez, transforma a figura
da parte esquerda na figura da parte direita é:
Obs: esse comando cria múltiplas cópias de uma ou mais
entidades.
Texto – A eficácia das palavras certas
Havia um cego sentado numa calçada em Paris. A seus pés, um
boné e um cartaz em madeira escrito com giz branco gritava:
"Por favor, ajude-me. Sou cego". Um publicitário da área de
criação, que passava em frente a ele, parou e viu umas poucas
moedas no boné. Sem pedir licença, pegou o cartaz e com o giz
escreveu outro conceito. Colocou o pedaço de madeira aos pés
do cego e foi embora.
Ao cair da tarde, o publicitário voltou a passar em frente ao cego
que pedia esmola. Seu boné, agora, estava cheio de notas e
moedas. O cego reconheceu as pegadas do publicitário e
perguntou se havia sido ele quem reescrevera o cartaz,
sobretudo querendo saber o que ele havia escrito.
O publicitário respondeu: "Nada que não esteja de acordo com o
conceito original, mas com outras palavras". E, sorrindo,
continuou o seu caminho. O cego nunca soube o que estava
escrito, mas seu novo cartaz dizia: "Hoje é primavera em Paris e
eu não posso vê-la". (Produção de Texto, Maria Luíza M. Abaurre
e Maria Bernadete M. Abaurre)
A frase abaixo em que a substituição de uma oração reduzida por uma desenvolvida equivalente é inadequada é:
READ TEXT I AND ANSWER QUESTIONS 16 TO 20
TEXT I
Will computers ever truly understand what we're saying?
Date: January 11, 2016
Source University of California - Berkeley
Summary:
If you think computers are quickly approaching true human
communication, think again. Computers like Siri often get
confused because they judge meaning by looking at a word's
statistical regularity. This is unlike humans, for whom context is
more important than the word or signal, according to a
researcher who invented a communication game allowing only
nonverbal cues, and used it to pinpoint regions of the brain where
mutual understanding takes place.
From Apple's Siri to Honda's robot Asimo, machines seem to be
getting better and better at communicating with humans. But
some neuroscientists caution that today's computers will never
truly understand what we're saying because they do not take into
account the context of a conversation the way people do.
Specifically, say University of California, Berkeley, postdoctoral
fellow Arjen Stolk and his Dutch colleagues, machines don't
develop a shared understanding of the people, place and
situation - often including a long social history - that is key to
human communication. Without such common ground, a
computer cannot help but be confused.
“People tend to think of communication as an exchange of
linguistic signs or gestures, forgetting that much of
communication is about the social context, about who you are
communicating with," Stolk said.
The word “bank," for example, would be interpreted one way if
you're holding a credit card but a different way if you're holding a
fishing pole. Without context, making a “V" with two fingers
could mean victory, the number two, or “these are the two
fingers I broke."
“All these subtleties are quite crucial to understanding one
another," Stolk said, perhaps more so than the words and signals
that computers and many neuroscientists focus on as the key to
communication. “In fact, we can understand one another without
language, without words and signs that already have a shared
meaning."
(Adapted from http://www.sciencedaily.com/releases/2016/01/1
60111135231.htm)
According to the researchers from the University of California, Berkeley:
READ TEXT II AND ANSWER QUESTIONS 21 TO 25:
TEXT II
The backlash against big data
[…]
Big data refers to the idea that society can do things with a large
body of data that weren't possible when working with smaller
amounts. The term was originally applied a decade ago to
massive datasets from astrophysics, genomics and internet
search engines, and to machine-learning systems (for voicerecognition
and translation, for example) that work
well only when given lots of data to chew on. Now it refers to the
application of data-analysis and statistics in new areas, from
retailing to human resources. The backlash began in mid-March,
prompted by an article in Science by David Lazer and others at
Harvard and Northeastern University. It showed that a big-data
poster-child—Google Flu Trends, a 2009 project which identified
flu outbreaks from search queries alone—had overestimated the
number of cases for four years running, compared with reported
data from the Centres for Disease Control (CDC). This led to a
wider attack on the idea of big data.
The criticisms fall into three areas that are not intrinsic to big
data per se, but endemic to data analysis, and have some merit.
First, there are biases inherent to data that must not be ignored.
That is undeniably the case. Second, some proponents of big data
have claimed that theory (ie, generalisable models about how the
world works) is obsolete. In fact, subject-area knowledge remains
necessary even when dealing with large data sets. Third, the risk
of spurious correlations—associations that are statistically robust
but happen only by chance—increases with more data. Although
there are new statistical techniques to identify and banish
spurious correlations, such as running many tests against subsets
of the data, this will always be a problem.
There is some merit to the naysayers' case, in other words. But
these criticisms do not mean that big-data analysis has no merit
whatsoever. Even the Harvard researchers who decried big data
"hubris" admitted in Science that melding Google Flu Trends
analysis with CDC's data improved the overall forecast—showing
that big data can in fact be a useful tool. And research published
in PLOS Computational Biology on April 17th shows it is possible
to estimate the prevalence of the flu based on visits to Wikipedia
articles related to the illness. Behind the big data backlash is the
classic hype cycle, in which a technology's early proponents make
overly grandiose claims, people sling arrows when those
promises fall flat, but the technology eventually transforms the
world, though not necessarily in ways the pundits expected. It
happened with the web, and television, radio, motion pictures
and the telegraph before it. Now it is simply big data's turn to
face the grumblers.
(From http://www.economist.com/blogs/economist explains/201
4/04/economist-explains-10)
The base form, past tense and past participle of the verb “fall” in “The criticisms fall into three areas” are, respectively:
READ TEXT II AND ANSWER QUESTIONS 21 TO 25:
TEXT II
The backlash against big data
[…]
Big data refers to the idea that society can do things with a large
body of data that weren't possible when working with smaller
amounts. The term was originally applied a decade ago to
massive datasets from astrophysics, genomics and internet
search engines, and to machine-learning systems (for voicerecognition
and translation, for example) that work
well only when given lots of data to chew on. Now it refers to the
application of data-analysis and statistics in new areas, from
retailing to human resources. The backlash began in mid-March,
prompted by an article in Science by David Lazer and others at
Harvard and Northeastern University. It showed that a big-data
poster-child—Google Flu Trends, a 2009 project which identified
flu outbreaks from search queries alone—had overestimated the
number of cases for four years running, compared with reported
data from the Centres for Disease Control (CDC). This led to a
wider attack on the idea of big data.
The criticisms fall into three areas that are not intrinsic to big
data per se, but endemic to data analysis, and have some merit.
First, there are biases inherent to data that must not be ignored.
That is undeniably the case. Second, some proponents of big data
have claimed that theory (ie, generalisable models about how the
world works) is obsolete. In fact, subject-area knowledge remains
necessary even when dealing with large data sets. Third, the risk
of spurious correlations—associations that are statistically robust
but happen only by chance—increases with more data. Although
there are new statistical techniques to identify and banish
spurious correlations, such as running many tests against subsets
of the data, this will always be a problem.
There is some merit to the naysayers' case, in other words. But
these criticisms do not mean that big-data analysis has no merit
whatsoever. Even the Harvard researchers who decried big data
"hubris" admitted in Science that melding Google Flu Trends
analysis with CDC's data improved the overall forecast—showing
that big data can in fact be a useful tool. And research published
in PLOS Computational Biology on April 17th shows it is possible
to estimate the prevalence of the flu based on visits to Wikipedia
articles related to the illness. Behind the big data backlash is the
classic hype cycle, in which a technology's early proponents make
overly grandiose claims, people sling arrows when those
promises fall flat, but the technology eventually transforms the
world, though not necessarily in ways the pundits expected. It
happened with the web, and television, radio, motion pictures
and the telegraph before it. Now it is simply big data's turn to
face the grumblers.
(From http://www.economist.com/blogs/economist explains/201
4/04/economist-explains-10)
The phrase “lots of data to chew on” in Text II makes use of figurative language and shares some common characteristics with:
Texto – A eficácia das palavras certas
Havia um cego sentado numa calçada em Paris. A seus pés, um
boné e um cartaz em madeira escrito com giz branco gritava:
"Por favor, ajude-me. Sou cego". Um publicitário da área de
criação, que passava em frente a ele, parou e viu umas poucas
moedas no boné. Sem pedir licença, pegou o cartaz e com o giz
escreveu outro conceito. Colocou o pedaço de madeira aos pés
do cego e foi embora.
Ao cair da tarde, o publicitário voltou a passar em frente ao cego
que pedia esmola. Seu boné, agora, estava cheio de notas e
moedas. O cego reconheceu as pegadas do publicitário e
perguntou se havia sido ele quem reescrevera o cartaz,
sobretudo querendo saber o que ele havia escrito.
O publicitário respondeu: "Nada que não esteja de acordo com o
conceito original, mas com outras palavras". E, sorrindo,
continuou o seu caminho. O cego nunca soube o que estava
escrito, mas seu novo cartaz dizia: "Hoje é primavera em Paris e
eu não posso vê-la". (Produção de Texto, Maria Luíza M. Abaurre
e Maria Bernadete M. Abaurre)
A frase abaixo em que o emprego do demonstrativo sublinhado está inadequado é:
Após a extração de uma amostra, as observações obtidas são
tabuladas, gerando a seguinte distribuição de frequências:

Considerando que E(X ) = Média de X, Mo(X ) = Moda de X e Me(X )
= Mediana de X, é correto afirmar que:
O elemento pré-moldado, que é executado industrialmente, mesmo em instalações temporárias em canteiros de obra, sob condições rigorosas de controle de qualidade é o elemento:
Com relação à execução de pintura intumescente, analise as afirmativas a seguir: ( ) Antes da aplicação da tinta intumescente, o substrato da estrutura precisa estar jateado, liso ou escovado, após o que deve estar completamente limpo e seco, sem óleo, umidade ou sujeira. ( ) Com o uso de um misturador elétrico ou outro equipamento apropriado, o primer é homogeneizado para que grumos sejam eliminados, sem acréscimo de água ou solvente. ( ) Após a aplicação do primer sobre o substrato da estrutura de maneira uniforme e secagem deste por 24 horas, a tinta intumescente, preparada da mesma maneira que o primer, é aplicada com o uso de rolo, trincha ou máquina aspersora. Sendo V para a(s ) afirmativa(s ) verdadeira(s ) e F para a(s ) falsa(s), a sequência correta é:
Relacione o tipo de material betuminoso empregado na pavimentação com sua respectiva característica. 1.Cimento asfáltico de petróleo 2.Asfalto diluído de cura média 3.Asfalto diluído de cura rápida 4.Emulsão asfáltica ( ) material resultante da diluição de um cimento asfáltico de petróleo em um diluente tipo nafta. ( ) material resultante da dispersão de um cimento asfáltico de petróleo em água, obtido com o auxílio de um agente que apresenta partículas carregadas eletricamente. ( ) asfalto obtido pela refinação do petróleo, de acordo com métodos adequados, de maneira a apresentar as qualidades necessárias para a sua utilização em construções de pavimentos asfálticos. ( ) material resultante da diluição de um cimento asfáltico de petróleo em um diluente tipo querosene. A relação correta, de cima para baixo, é:
Considere as seguintes informações sobre tipos de controle da resistência do concreto, X e Y: X: são retirados exemplares de algumas betonadas de concreto, cujas amostras apresentem no mínimo seis ou doze exemplares, de acordo com a classe do concreto; Y: consiste no ensaio de exemplares de cada betonada de concreto, sem haver limitação para o número de exemplares do lote. Analisando as informações de cada uma, conclui-se que: