
No projeto lógico de um banco de dados relacional, após a tradução das entidades para tabelas, a tradução dos relacionamentos binários é feita de três formas básicas. Quais sejam:
I. Criação de tabela própria para o relacionamento.
II. Adição de colunas em uma tabela de entidade.
III. Adição de registros em uma tabela de entidade.
IV. Fusão de tabelas de relacionamentos.
V. Fusão de tabelas de entidades.
Quais estão corretas?
Após ter sido privatizada, determinada empresa passou a utilizar novos sistemas administrativos, tais como: folha de pagamento, sistema de pessoal, sistemas de benefícios etc.; porém, constatou-se que os sistemas antigos não poderiam ser descontinuados em um pequeno espaço de tempo. Tais sistemas usavam tecnologias de armazenamento de dados antiquados e dados de baixa qualidade.
Acerca dessa situação hipotética e considerando aspectos diversos pertinentes à inteligência de negócios - business intelligence (BI) -, julgue o seguinte item.
Na situação hipotética em tela, considerando as bases de dados antigas e novas, seria uma ótima prática a utilização dos conceitos de data warehouse e data mining para, por exemplo, automatizar a análise de currículos de acordo com as competências dos empregados
Tabela TURFE
Considere um banco de dados relacional que contém uma única tabela, TURFE, cuja estrutura é exibida com sua instância, a seguir.

Para cada páreo, ou corrida, são armazenados os nomes dos cavalos participantes e os respectivos tempos. A classificação de cada cavalo numa corrida segue a ordem crescente de tempo. Não há empates.
Com relação à tabela TURFE, descrita anteriormente, o comando SQL que exibe, para cada páreo, somente o cavalo que chegou em último lugar com o respectivo tempo é:
Com relação à tabela TURFE, descrita anteriormente, analise o comando SQL a seguir.

O número de linhas do resultado produzido pela execução do comando acima, excetuada a linha de títulos, é:
No contexto do MySQL 8.x, considere as afirmativas a respeito da utilização de índices do tipo FULLTEXT exibidas a seguir.
I. Índices FULLTEXT podem ser aplicados somente para tabelas MyISAM.
II. Consultas baseadas em índices FULLTEXT devem usar a sintaxe
MATCH(col1, col2, ...) AGAINST(expressão [modificador]).
III. O comando ALTER TABLE não pode ser utilizado para a criação de índices FULLTEXT.
Está correto somente o que se afirma em:
Nas próximas cinco questões, considere as tabelas T1, T2 e T3, cujas estruturas e instâncias são exibidas a seguir. O valor NULL deve ser tratado como unknown (desconhecido).
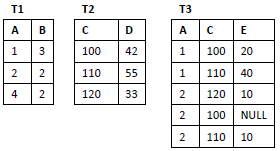
Suponha que as tabelas T1 e T2, descritas anteriormente, tenham sido declaradas com as colunas A e C, respectivamente, definidas como chaves primárias.
Para tanto, a definição de chaves estrangeiras na tabela T3 deveria ter como base o script:
ATENÇÃO!
Na próxima questão, considere as tabelas de banco de dados T, TX e DUAL, exibidas com suas respectivas instâncias a seguir.
T



O comando SQL utilizado nessa atualização é exibido a seguir.

ATENÇÃO!
Para a questão a seguir, considere uma tabela relacional R, com atributos W, X, Y, Z, e o conjunto de dependências funcionais identificadas para esses atributos.
X → Y
X → Z
Z → X
Z → W
(1) X → Y Z W
No PostgreSQL, para fazer backup full de todo o cluster, incluindo schemas, bancos de dados, tabelas, templates, usuários e roles, assim como suas permissões, utiliza-se o comando cuja sintaxe está abaixo:
-p -U -h -f <path/nome_arquivo_backup>
Na sintaxe apresentada, refere-se à
Um dicionário de dados é útil
Assinale a opção que apresenta um princípio de dados abertos em que todos os dados públicos são disponibilizados, não se limitando a documentos, banco de dados, transcrições e gravações audiovisuais.
No CRISP-DM, a fase que se caracteriza pelas tarefas de limpar, construir, integrar e formatar os dados é a de
Maria está explorando a seguinte tabela da base de dados de vendas do mercado HortVega:

Utilizando técnicas de Mineração de Dados, Maria encontrou a seguinte informação:
Se um cliente compra Cacau, a probabilidade de ele comprar chia é de 50%. Cacau => Chia, suporte = 50% e confiança = 66,7%.
Para explorar a base de dados do HortVega, Maria utilizou a técnica de Mineração de Dados:
No contexto do MySQL, analise as afirmativas a seguir a respeito da carga de dados (Bulk Data Loading) para tabelas InnoDB.
I. No caso da existência de restrições (constraints) do tipo UNIQUE, é possível suspender temporariamente a verificação com o comando SET unique_checks=1.
II. Tabelas InnoDB utilizam índices clusterizados, o que normalmente torna mais rápida a carga de dados dispostos na mesma ordem da chave primária (primary key).
III. Na carga de arquivos muito grandes, a shell do MySQL oferece serviços de importação rápida por meio do utilitário util.importTable().
Está correto somente o que se afirma em:
Um programador criou uma tabela chamada “funcionarios” em um banco de dados Oracle Database Express Edition 11g, mas foi alertado que na empresa existe um padrão em que os nomes das tabelas devem começar por “tb_”. Qual alternativa representa uma solução válida para alterar o nome da tabela?