
Analise o código Python a seguir.

Assinale a opção que indica os valores exibidos na execução desse código.
Considere a seguinte série temporal:
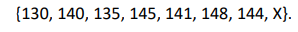
Aplicando o método de previsão de médias de dois pontos de dados, o valor para a projeção do oitavo item (X) será
O objetivo principal do uso de técnicas de Agrupamento (Clustering) em Análise de Dados é dividir um grande conjunto de dados em subconjuntos, agrupando elementos similares em categorias distintas.
Assinale a opção que indica o tipo de algoritmo que não se enquadra nessa descrição.
Num banco de dados relacional, considere uma tabela R, com duas colunas A e B, ambas do tipo string de caracteres, cuja instância é
exibida a seguir.
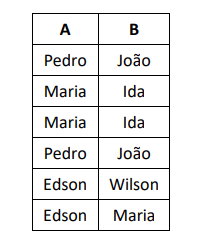
Nesse cenário analise os comandos a seguir.

Assinale a lista que contém o número de registros deletados em cada um dos comandos I, II e III, respectivamente, quando executados separadamente e usando a mesma instância inicial descrita.
Bancos de dados NoSQL são usualmente divididos em categorias de store.
Assinale a opção que apresenta o tipo de store que privilegia velocidade, capacidade de leitura e escrita e estruturas de dados flexíveis, sem a necessidade de esquemas estabelecidos previamente.
A Análise de Componentes Principais (PCA) é uma técnica de transformação de dados que tem como objetivo encontrar as direções de maior variação nos dados, geralmente representadas pelos chamados componentes principais, e gerar novas representações dos dados.
Assinale o objetivo principal dessa técnica.
Os principais Sistemas Gerenciadores de Bancos de Dados oferecem total suporte à linguagem SQL. Um aspecto importante da implementação do SQL é o tratamento para valores nulos quando esses são considerados como unknown values. Nesse contexto, considere uma tabela T com colunas A e B, que podem conter valores nulos. T possui 100 registros e, em 50% das linhas, há pelo menos uma coluna preenchida com o valor NULL.
Considere a consulta a seguir:
![]()
O número máximo de linhas de resultados que seriam retornadas pela consulta é igual a
Considere um banco de dados relacional em que as operações de insert e update efetuadas numa certa tabela devem ser monitoradas e anotadas, como subsídio aos procedimentos de auditoria da empresa. Essa tabela é utilizada por uma série de aplicações, em diferentes tipos de transações, e iniciadas por um número considerável de usuários.
Nesse cenário, assinale o mecanismo mais adequado para a implementação desse monitoramento.