
ATENÇÃO!
Na próxima questão, considere as tabelas de banco de dados T, TX e DUAL, exibidas com suas respectivas instâncias a seguir.
T



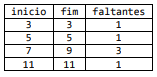
O comando SQL que produz o resultado acima, a partir da instância inicialmente definida para a tabela T, é:
Em um problema de classificação é entregue ao cientista de dados um par de covariáveis, (x1 , x2 ), para cada uma das quatro observações a seguir: (6,4), (2,8), (10,6) e (5,2). A variável resposta observada nessa amostra foi “Sim”, “Não”, “Sim”, “Não”, respectivamente.
A partição que apresenta o menor erro de classificação quando feita na raiz (primeiro nível) de uma árvore de decisão é:
ATENÇÃO!
Na próxima questão, considere as tabelas de banco de dados T, TX e DUAL, exibidas com suas respectivas instâncias a seguir.
T
O comando SQL utilizado nessa atualização é exibido a seguir.

ATENÇÃO!
Para a questão a seguir, considere uma tabela relacional R, com atributos W, X, Y, Z, e o conjunto de dependências funcionais identificadas para esses atributos.
X → Y
X → Z
Z → X
Z → W
(1) X → Y Z W
ATENÇÃO!
Para a questão a seguir, considere uma tabela relacional R, com atributos W, X, Y, Z, e o conjunto de dependências funcionais identificadas para esses atributos.
X → Y
X → Z
Z → X
Z → W
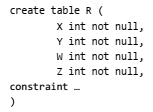
De acordo com as dependências funcionais de R, e com a Forma Normal de Boyce-Codd, a definição correta das chaves (por meio de constraints) aplicáveis e necessárias para essa tabela deveria ser:
Um analista de dados deseja criar um modelo para classificação de documentos em duas categorias: sigilosos e públicos. À sua disposição, existe um conjunto de dados com N documentos, dos quais uma fração α deles é sigilosa. O analista quer escolher uma fração β dos N documentos para pertencer ao conjunto de teste. O objetivo é garantir que cada uma das classes (documentos sigilosos e públicos) seja responsável, em média, por ao menos 10% do total de documentos. Essa restrição precisa ser válida tanto no conjunto de treino quanto no conjunto de teste. Um par (α,β) que satisfaz as restrições do analista é:
ATENÇÃO!
Na próxima questão, considere as tabelas de banco de dados T, TX e DUAL, exibidas com suas respectivas instâncias a seguir.
T
(1) select * from dual where x = null