
Durante o mapeamento do Modelo Entidade-Relacionamento (MER) para o modelo relacional de dados, aplicam-se regras específicas para transformar cada componente conceitual em elementos do modelo relacional.
Considere as seguintes situações:
• Autorrelacionamentos - quando uma entidade se relaciona consigo mesma.
• Hierarquias IS-A - generalização/especialização de entidades.
• Relacionamentos 1:N - em que cada instância de uma entidade do lado “1” pode associar-se a várias instâncias da entidade do lado “N”, mas cada instância do lado “N” está associada a exatamente uma do lado “1”.
• Relacionamentos N:N - em que cada instância de uma entidade pode relacionar-se com várias instâncias da outra e vice-versa.
• Entidades com atributos multivalorados - em que um atributo pode ter múltiplos valores para uma mesma instância.
Nesse contexto, as transformações recomendadas para essas cinco situações são as seguintes:
No que diz respeito aos processos de generalização e especialização na modelagem de entidades e relacionamentos (MER), originalmente proposta por Peter Chen, considere as afirmativas a seguir.
I - Em uma hierarquia de especialização, podem-se definir restrições de completude (total ou parcial) e de disjunção (disjunta ou sobreposta) para determinar, respectivamente, se todas as instâncias do supertipo devem pertencer a algum subtipo e se uma instância pode ou não pertencer a mais de um subtipo simultaneamente.
II - Na hierarquia de generalização/especialização, a herança de atributos ocorre dos subtipos para o supertipo, permitindo que o supertipo adquira atributos específicos definidos nas especializações.
III - A generalização consiste em identificar e agrupar atributos comuns a um conjunto de entidades para formar um supertipo, do qual os subtipos (especializações) herdam esses atributos.
É correto o que se afirma em
A tabela TAB, apresentada a seguir, armazena informações sobre agências bancárias:
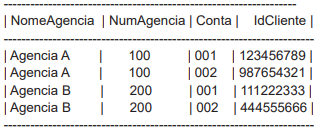
Considere que (NumAgencia, Conta) é a única chave candidata para TAB e, também, que as seguintes dependências funcionais (DF) são válidas para TAB:
NumAgencia → NomeAgencia
(NumAgencia, Conta) → IdCliente
No cenário apresentado, a tabela TAB não está na segunda forma normal (2FN), pois
Assinale a opção em que é citado o processo que, no gerenciamento de identidade e acesso, corresponde à criação e ao gerenciamento de contas de usuário, incluindo-se a especificação dos usuários e dos recursos a que eles têm acesso bem como a atribuição de permissões e níveis de acesso.
Considere duas transações, T1 e T2, que efetuam operações de bloqueio (lock) e desbloqueio (unlock), além de operações de leitura (read) e gravação (write), sobre itens P e Q em um banco de dados relacional. Um SGBD precisa definir um escalonamento (schedule) que execute essas duas transações intercaladas no tempo, satisfazendo o protocolo de controle de concorrência por bloqueio em duas fases (2PL - 2 phase locking).
Qual escalonamento satisfaz o protocolo 2PL?
No modelo de dados relacional, as tuplas (ou linhas) em uma relação (ou tabela) não possuem ordem definida; entretanto, os atributos (ou colunas) possuem uma ordem arbitrária determinada por seu esquema.
Nesse modelo, a característica descrita
A arquitetura padrão ANSI para SGBDs é dividida nos três seguintes níveis:
• Externo: visões específicas dos usuários do sistema de banco de dados;
• Conceitual: modelo lógico do banco de dados;
• Interno: representação física para o armazenamento dos dados.
Nesse contexto, quando se considera o princípio da independência de dados, verifica-se que
No modelo de dados relacional, as restrições de integridade semântica, ou regras de negócio (business rules), expressam condições que refletem as políticas e os procedimentos específicos de uma organização.
Para garantir que essas restrições sejam corretamente aplicadas na criação de um banco de dados, é necessário utilizar
Em bancos de dados relacionais, as visões são tabelas virtuais definidas por consultas SQL que fornecem uma abstração sobre os dados das tabelas-base.
Contudo, quando uma visão envolve operações de junção (join) entre duas ou mais tabelas,
Em um determinado modelo conceitual, representado pelo modelo de entidades e relacionamentos, há duas entidades, Cliente e Pedido, e um único relacionamento, chamado Realiza, entre essas entidades. Sabe-se que:
(1) cada pedido deve ser realizado por exatamente um cliente de cada vez; e
(2) um cliente pode realizar vários pedidos, mas nem todo cliente faz pedidos.
Nesse cenário, as cardinalidades (min, max), para cada lado desse relacionamento entre Clientes e Pedidos, devem ser representadas por
Um funcionário da área de desenvolvimento trabalha com bancos de dados de diversas áreas de uma empresa. Ele precisa, utilizando o comando CREATE TABLE da linguagem relacional SQL, criar uma tabela em um desses bancos de dados.
A sintaxe correta desse comando é apresentada em
Em 1976, Peter Chen propôs o Modelo Entidade-Relacionamento (MER) para projetos de bancos de dados.
No MER, um atributo composto é aquele que se aplica às(aos)
Analise as seguintes afirmações sobre indexação em bancos de dados relacionais.
I - Índices B-tree organizam os dados em uma árvore de busca balanceada, permitindo consultas por intervalos e operações de comparação e ordenação.
II - Índices Hash são adequados para operações de comparações por igualdade, utilizando funções de aleatorização para mapear as chaves de busca aos endereços dos registros físicos.
III - Índices Bitmap são especialmente úteis para representar categorias de valores no domínio de atributos (colunas).
IV - os índices, independentemente do tipo, garantem que os registros correspondentes às tuplas de uma tabela sejam armazenados fisicamente na ordem determinada pela chave de índice, o que acelera tanto as consultas quanto as inserções.
É correto APENAS o que se afirma em
Em relação a banco de dados, julgue os próximos itens.
De forma geral, ETL é normalmente usado para dados totalmente estruturados, enquanto ELT atende bem principalmente dados semiestruturados e(ou) não estruturados.
No que se refere a Big Data e analytics, julgue os itens a seguir.
Em Big Data, um pipeline de dados visa refinar e limpar os dados brutos, facilitando a utilização desses dados pelos usuários finais.