
Considerando a seguinte matriz de confusão obtida de um experimento de classificação:
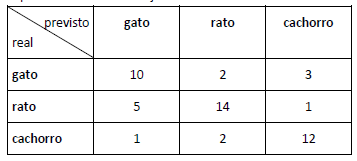
Os valores corretos das métricas de precisão e recall (revocação/sensibilidade), para a classe rato, são, respectivamente:
Julgue o item a seguir, relativo a aprendizado supervisionado.
Em se tratando de modelos de regressão linear, indica-se a utilização dos seguintes métodos não paramétricos para a estimação dos resultados: mínimos quadrados (MQ) e de support vector machines (SVM).
Em relação a aprendizado não supervisionado, julgue o item que se segue.
O algoritmo random forest é um algoritmo de aprendizado de máquina supervisionado em que se agrupam os resultados de várias árvores de decisão de cada nó para se obter uma
conclusão própria e aumentar a precisão do modelo, não sendo o referido algoritmo adequado para grandes conjuntos de dados.
Durante o processo de treinamento e validação de uma rede neural, foi observado o fenômeno de underfitting do modelo, necessitando de ajustes ao procedimento. A arquitetura utilizada foi a Multilayer Perceptron (MLP) e o conjunto de dados foi separado em regime de holdout (50%, 30% e 20% para treinamento, validação e teste, respectivamente).
Dois fatores que podem ter condicionado o fenômeno observado são:
A tradução automática de texto, embora possua raízes na metade do século passado, vem recebendo melhorias substanciais na última década, alimentadas pelo crescimento do poder computacional, disponibilidade de dados linguísticos e inovações técnicas.
Com relação às inovações, e levando em consideração os recursos mencionados, a alternativa que apresenta apenas vantagens da Tradução Automática Neural (NMT) sobre técnicas de Tradução Automática Estatística (SMT) é:
Julgue o item a seguir, relativo a aprendizado supervisionado.
O trade off entre variância e viés é afetado pela utilização de polinômios, com graus que variam de zero a três, em que o emprego de polinômios de ordem ímpar produz sempre melhores resultados no que diz respeito à redução da variância e viés que os de ordem par, seja para estimativas com regressões locais constantes e lineares, seja para as estimativas de ordem quadrática e cúbica.
Em relação a aprendizado não supervisionado, julgue o item que se segue.
A ação de realizar agrupamento hierárquico tem como premissa básica encontrar elementos em um conjunto de dados que impliquem a presença de outros elementos na mesma transação, com um grau de certeza definido pelos índices de fator de suporte e o fator de confiança, que pode ser realizado, por exemplo, por meio do algoritmo a priori.
Durante o treinamento de uma rede neural artificial para classificação de imagens, foi observado o comportamento descrito pelo gráfico abaixo, que mostra a evolução do erro conforme o número de iterações.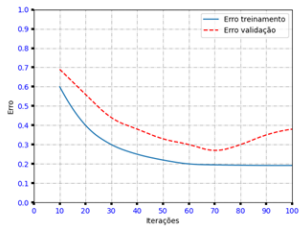
O classificador em questão foi treinado em um conjunto de dados particionado (holdout) em 60%/30%/10% (treinamento/validação/ teste). Entretanto, os especialistas envolvidos consideraram o modelo obtido insatisfatório após analisarem o gráfico.
Considerando essas informações, duas técnicas que poderiam ser utilizadas para contornar o problema encontrado são:
Julgue o item a seguir, relativo a aprendizado supervisionado.
Considerando-se, nos gráficos a seguir, que o resultado #2 corresponda ao melhor desempenho do algoritmo, é correto afirmar que o resultado #1 indica que houve underfitting.
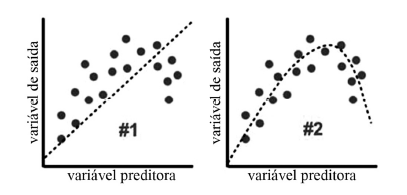
Em relação a aprendizado não supervisionado, julgue o item que se segue.
A validação cruzada pode ser utilizada para detectar quando uma rede neural está sendo treinada de maneira excessiva (overtraining) e assim interromper o treinamento antes que isso ocorra, como, por exemplo, por meio do princípio orientador atrativo para o ajuste dos pesos e bias durante o processo de treinamento da RNA.
Uma organização está implementando um sistema de busca de informações interno, e a equipe de desenvolvimento resolveu avaliar diferentes modelos de linguagem vetoriais que ajudariam a conectar melhor documentos e consultas em departamentos que usam terminologias distintas em áreas de negócio que se sobrepõem. Um dos analistas ressaltou que seria interessante guardar os vetores de todo o vocabulário do modelo em um cache, de forma a aumentar a eficiência de acesso e reduzir certos custos de implantação.
Das alternativas abaixo, aquela que lista apenas os modelos compatíveis com essa estratégia de caching é:
Após alguns resultados insatisfatórios usando funções de ativação linear em um projeto de rede neural artificial, um cientista de dados resolve tentar outras funções e recebe algumas sugestões de um colega.
Dadas as alternativas abaixo, cada uma representando uma sugestão de função recebida, aquela que apresenta uma função apropriada ao uso como ativação em uma rede neural é:
Em relação a aprendizado não supervisionado, julgue o item que se segue.
O modelo de mistura gaussiana (GMM) é um método que descreve um agrupamento de amostras para determinado espaço de características, em que o GMM é uma mistura de K distribuições gaussianas associadas à mudança de estado dos pixels.
Julgue o item a seguir, relativo a aprendizado supervisionado.
A despeito do alto grau de aplicabilidade das técnicas de regularização na classificação e na regressão, no que se refere à sua acurácia, tais técnicas tendem a causar o sobreajuste (overfitting) devido à influência de coeficientes responsáveis por flutuações excessivas.
Ao tentar resolver um problema de aprendizado de máquina que separava um evento entre duas classes, um desenvolvedor encontrou uma acurácia de exatamente 90%.
Analisando a matriz de confusão, o desenvolvedor constatou que os verdadeiros positivos eram 14169, que os verdadeiros negativos eram 15360, os falsos positivos eram 1501, e os falsos negativos eram