
A tabela presente no código em R abaixo apresenta a quantidade de processos analisados por três analistas (denotados por A1, A2 e A3) em diferentes anos.
dados = tibble::tibble(Analista=c(“A1”, “A1”, “A1”, “A2”, “A2”, “A3”, “A3”, “A3”),
Ano=c(2018,2019,2020,2019,2020,2018,2019,2020), Processos=c(10,15,20,25,20,8,7,12))
Um programador roda o código abaixo em R.
tidyr::pivot_wider(data=dados, names_from=”Analista”, values_from=”Processos”)
Os valores esperados na primeira linha do objeto resultante do comando acima são:
Um analista do TCU gostaria de aplicar um modelo de Latent Dirichlet Allocation (LDA) em um conjunto de textos. A alternativa que melhor descreve o resultado do modelo é:
Durante o treinamento de uma rede neural artificial para classificação de imagens, foi observado o comportamento descrito pelo gráfico abaixo, que mostra a evolução do erro conforme o número de iterações.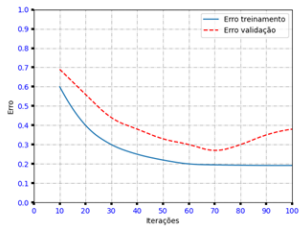
O classificador em questão foi treinado em um conjunto de dados particionado (holdout) em 60%/30%/10% (treinamento/validação/ teste). Entretanto, os especialistas envolvidos consideraram o modelo obtido insatisfatório após analisarem o gráfico.
Considerando essas informações, duas técnicas que poderiam ser utilizadas para contornar o problema encontrado são:
Uma organização está implementando um sistema de busca de informações interno, e a equipe de desenvolvimento resolveu avaliar diferentes modelos de linguagem vetoriais que ajudariam a conectar melhor documentos e consultas em departamentos que usam terminologias distintas em áreas de negócio que se sobrepõem. Um dos analistas ressaltou que seria interessante guardar os vetores de todo o vocabulário do modelo em um cache, de forma a aumentar a eficiência de acesso e reduzir certos custos de implantação.
Das alternativas abaixo, aquela que lista apenas os modelos compatíveis com essa estratégia de caching é: